What is Session Outcome?
Session Outcome is a key metric provided by Melodi designed to give you an immediate understanding of your AI agent’s performance from the perspective of user experience. In essence, it estimates whether a user had an overall positive interaction with your agent during a specific session. Think of it as an automated way to gauge user satisfaction, especially helpful because direct user feedback (like thumbs up/down ratings) is often sparse. While explicit feedback is valuable, it typically represents only a small fraction (often 1-20%) of total user sessions. Session Outcome bridges this gap by providing an estimated user experience score for every session, even those without explicit feedback. This allows you to monitor user experience trends consistently across your entire user base without requiring any additional setup or instrumentation.How does it work?
Melodi calculates Session Outcome by analyzing the conversation within each session. It looks at several factors:- Agent Responses: The relevance and quality of the agent’s answers in relation to the user’s queries.
- Conversation Flow: How the interaction progresses – does the user seem to achieve their goal, or do they appear frustrated or stuck?
- Explicit Feedback: If the user did provide feedback (e.g., a rating or comment), this is heavily weighted in the calculation.
- Other Contextual Clues: Factors like session length, user actions, and repetition can also inform the outcome score.
Why is it important?
- Comprehensive Monitoring: Get a view of user experience across all sessions, not just those with feedback.
- Identify Problem Areas: Quickly spot sessions or trends indicating poor user experience, allowing you to investigate and improve your agent.
- Track Improvements: Measure the impact of changes you make to your agent on overall user satisfaction.
- No Setup Required: Gain valuable insights out-of-the-box.
Using Session Outcome: The Experience Score
While every individual session receives an Outcome score, the real power comes from aggregating this data to understand broader trends. Melodi automatically calculates an Experience Score based on Session Outcomes in several key areas:- Overall: See the general experience trend across all users and sessions.
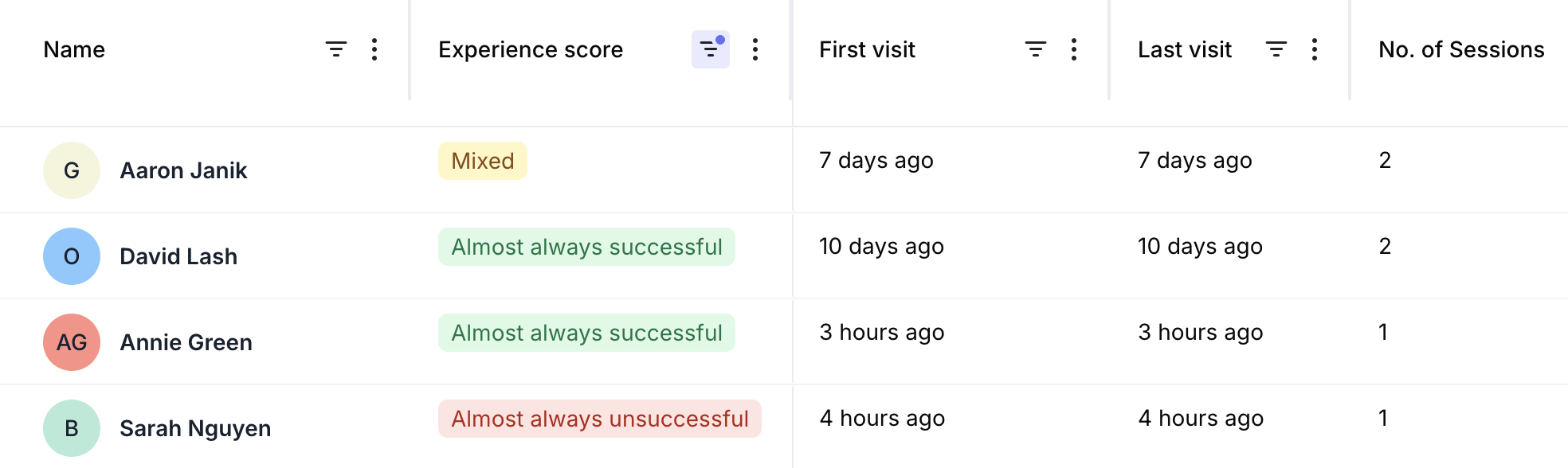
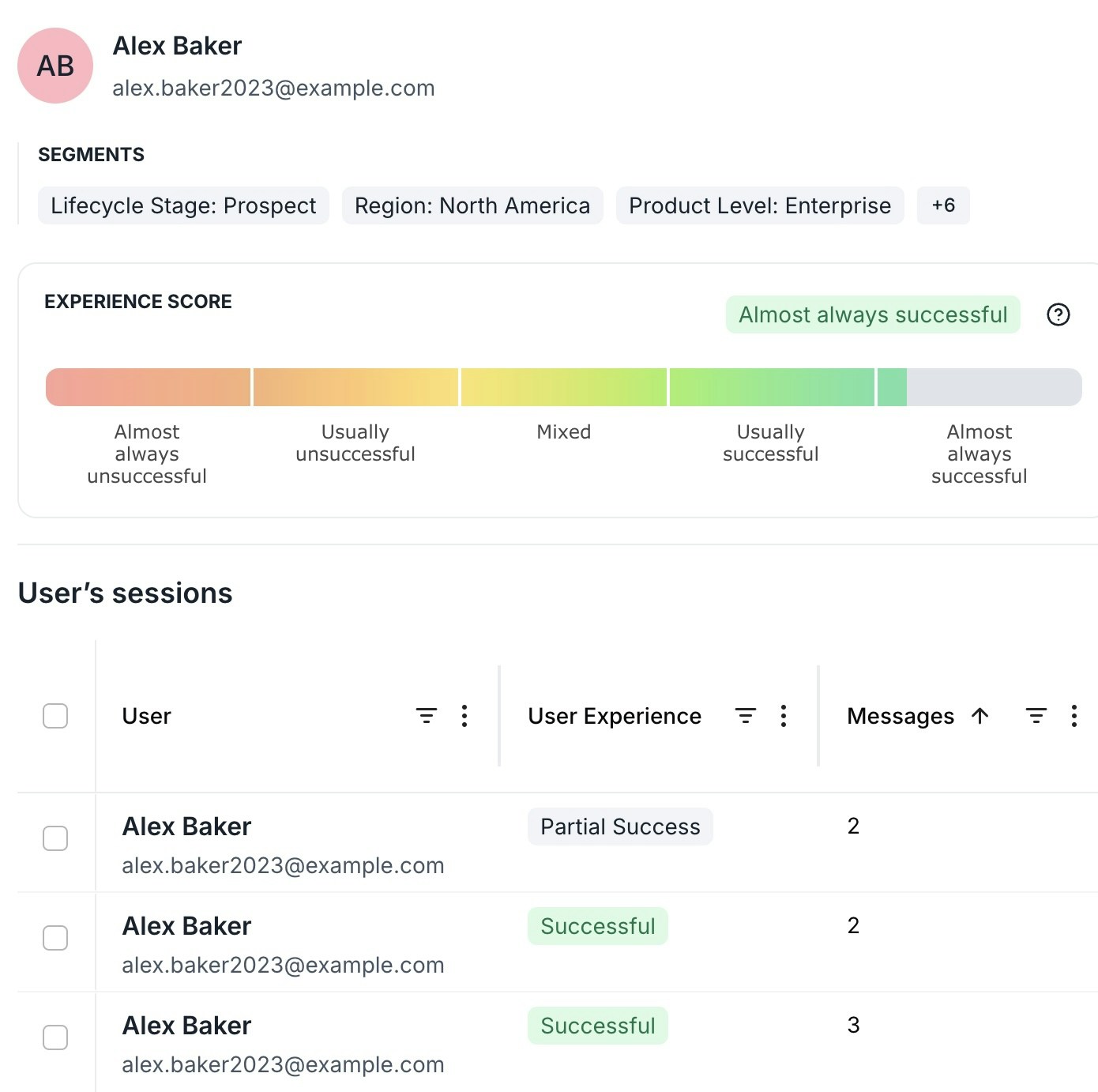
- Per User: Understand the typical experience for individual users over time.
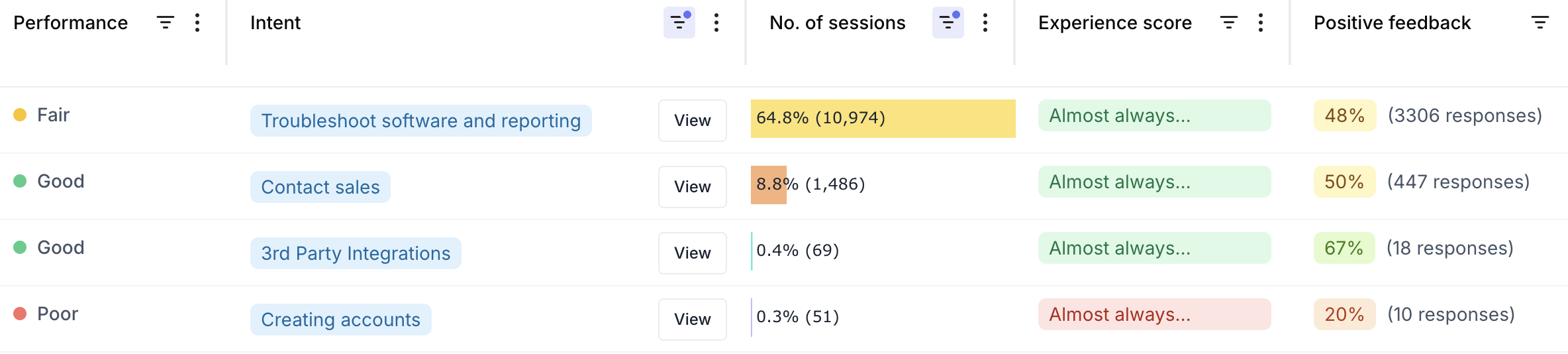
- Per User Intent: Analyze how successful interactions are when users try to accomplish specific goals (as defined by User Intents).
- Users Dashboard: See the overall Experience Score and scores for specific user segments.
-
- Individual User Record: View the historical Experience Score for a specific user.
-
- Intents Dashboard: Analyze the Experience Score for each configured User Intent, showing how well the agent performs specific tasks.
-
Technical Deep Dive
This section provides more technical detail for those interested in the underlying mechanics of the Session Outcome metric.
- Session Data Ingestion: Melodi processes the logged messages and metadata for each user session.
- Feature Extraction: Relevant features are extracted, including conversational turns, message content, timestamps, and any explicit user feedback signals or assigned attributes.
- LLM Evaluation: A specialized LLM prompt is constructed, incorporating the session context. The LLM is tasked with evaluating the session against criteria related to helpfulness, relevance, and indicators of user satisfaction or frustration, ultimately outputting a score or classification representing the session’s outcome.
- Calibration: The model’s output is calibrated using available explicit feedback data to improve the accuracy of the estimation for sessions without explicit feedback.