Overview: More Than Just Feedback
Melodi provides robust tools for capturing valuable insights directly from your users and internal teams. While you might think of this simply as “collecting feedback,” Melodi’s system is intentionally designed to bridge the gap between immediate user support and long-term AI improvement. This feedback cycle is a cornerstone of the Melodi Method, providing the raw material to identify improvement opportunities across all aspects of the agent – from source content to conversation design. Think of it this way:- For Product Managers & Operations: It’s a direct line to understanding user sentiment, identifying pain points, and enabling targeted outreach – much like a CSAT or bug reporting system.
- For Data Scientists & AI Teams: It’s a structured data labeling platform, producing high-quality datasets ready for ML tasks like fine-tuning models or creating few-shot examples.
- Collecting Feedback & Labels
- Customizing Feedback Types
- Reviewing Feedback (Feedback Inbox)
- Using Feedback Data for ML
Collecting Feedback & Labels
Data labels, universally referred to as “Feedback” within Melodi, can be collected from two primary sources:-
End-Users (via your Application):
- Melodi React Component: A convenient, drop-in component for adding feedback buttons (like thumbs up/down) directly to your UI. (See Component Docs)
- Feedback API: Integrate Melodi’s feedback endpoint with your own custom feedback interface (e.g., star ratings, surveys). (See API Docs)
-
Internal Teams (via Melodi Dashboard):
- Your internal subject matter experts, QA teams, or data labelers can review sessions directly within the Melodi platform and add feedback/labels.
Customizing Feedback Types
By default, Melodi includes “Positive” and “Negative” feedback types. However, you can customize this entirely to match your specific evaluation needs. Define your own feedback types or scoring systems, such as:- Star Ratings: 1-5 stars
- Quality Scores: “Excellent,” “Good,” “Fair,” “Poor”
- Sentiment: “Happy,” “Neutral,” “Frustrated”
- Relevance: “Relevant,” “Partially Relevant,” “Irrelevant”
- Task Completion: “Goal Achieved,” “Goal Not Achieved”
- Any other categorical or numerical scale relevant to your analysis.
Explicit vs. Implicit Feedback
Melodi supports collecting both explicit and implicit feedback signals via the API:- Explicit Feedback: Direct ratings or comments provided consciously by the user (e.g., clicking thumbs up).
- Implicit Feedback: Signals derived from user behavior that indicate success or failure, sent via the API (e.g., user accepts an AI-generated recommendation, user clicks “add to cart” after an interaction, user immediately closes the chat window).
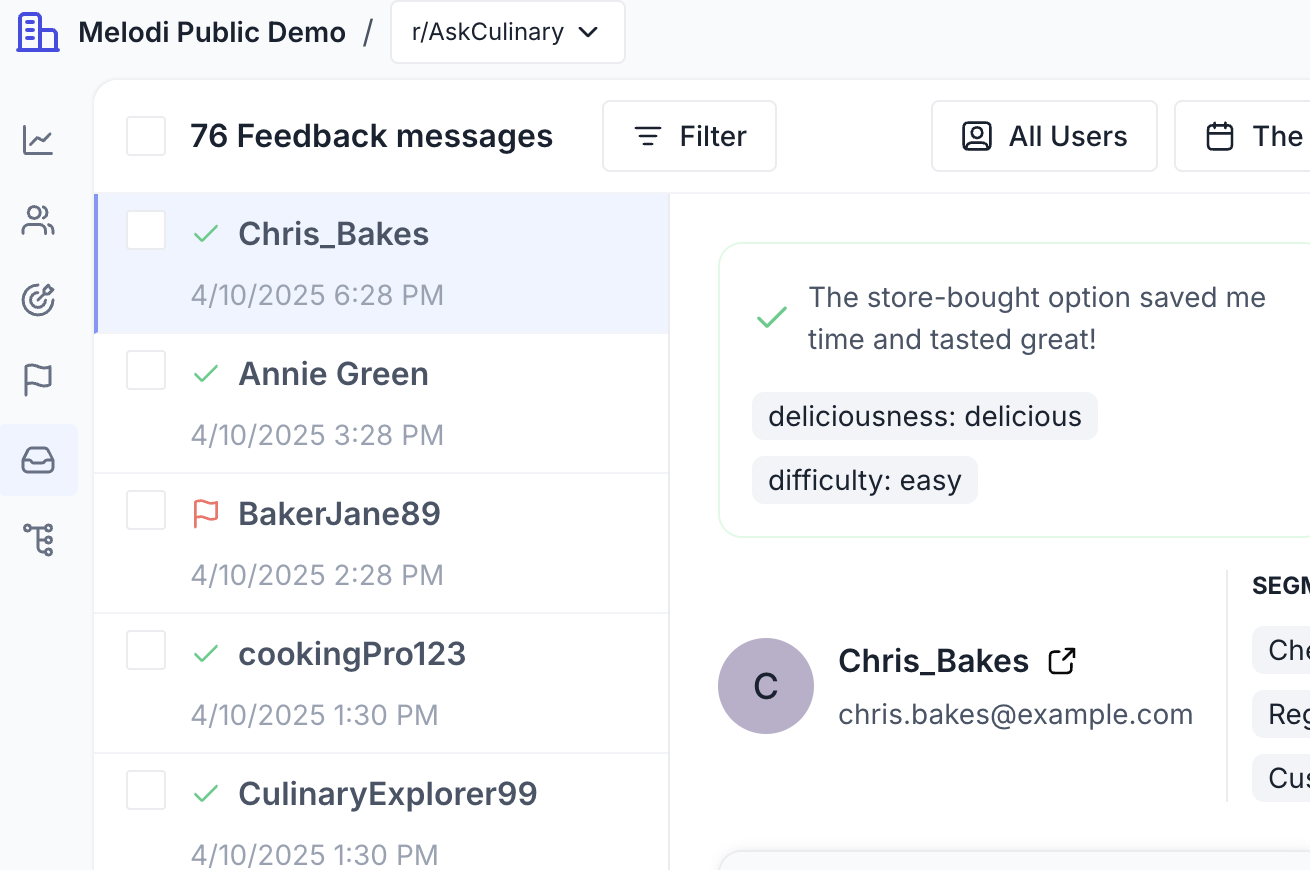
The Feedback Inbox: Review & Action
All feedback submitted by end-users lands in the Feedback Inbox within the Melodi dashboard. This serves multiple purposes:- Review & QA: Teams can review incoming user feedback for accuracy and consistency.
- User Outreach: Treat critical feedback as opportunities for direct user engagement, similar to support tickets or NPS follow-ups. Understand the context of the feedback by viewing the full session associated with it.
- Identify Trends: Spot recurring themes or issues highlighted by user feedback.
Leveraging Feedback for Machine Learning
The feedback collected (whether from end-users or internal reviewers) is structured within Melodi’s data model specifically to support AI development. Data scientists can easily retrieve labeled datasets for tasks like:- Fine-tuning: Use high-quality feedback data to improve the performance of your base models.
- Few-Shot Prompting: Extract examples of successful or failed interactions to use in prompts.
- Evaluation Set Creation: Build curated datasets for testing new model versions or prompts.
- Offline Analysis: Perform custom analysis on labeled data.
has_feedback=true query parameter when calling the Get Threads API endpoint.
Here’s a Python example using the Melodi SDK: